Text
updated for 5.10
The recognition of textual elements is delegated to the Tesseract OCR library.
The TEXTS step runs the OCR on the current sheet. We can also manually run the OCR on a selected collection of glyphs or even drag n’ drop text items from the Shape board.
Running the OCR results in one or several text words gathered in sentences, which we can further modify manually, in terms of:
- textual content,
- font attributes and size
- type of words and sentences,
- role of every sentence.
Table of contents
TEXTS step
The TEXTS step runs the OCR on the whole sheet image and tries to assign to each OCR’d item its content, attributes, size, type and role.
This engine step is influenced by three options available in the Book → Set book parameters menu:
- Support for chord names
- Support for lyrics (assumed to be located below the related staff)
- Support for lyrics even located above staff
Chord names and lyrics are special items; this is the reason why their recognition must be explicitly selected to avoid collateral damages of the OMR engine when they are not desired.
On the other hand, the metronome marks, thanks to their recognizable structuring, don’t require the setting of any specific option.
Manual OCR
The OCR can also be launched manually on a glyph(s) selection by pressing one of the buttons provided in the Texts palette of the Shape board:
- The
lyricbutton, - The
textbutton, - The
metronomebutton.

There are separate buttons because lyric items have a behavior significantly different from other text items – especially the gap between words can be much wider. And the metronome is a specific item on its own.
By manually choosing one button or another, we clearly specify the desired result type – and thus the sentence role – of the OCR operation.
We can as well drag n’ drop items from the same Texts palette.
In this case, no OCR is performed, and we have to manually enter every word content.
Sentence vs. Words
A Sentence inter is an ensemble of one or several Word inter(s):
-
Any
Wordhandles its textual content, font attributes, font size and location. We can manually modify any of these informations. -
A
Sentenceis a sequence of words (we can easily navigate from a selected word to its containing sentence via theToEnsemblebutton of the InterBoard).A sentence is assigned a role, which we can edit.
The sentence content is simply defined as the concatenation of the contents of its words members. Except for the case of
Metronome– which mixes text and music characters – we cannot modify a sentence content directly, but rather via each of its words members.Since release 5.10, we can also directly modify the sentence font attributes to apply them on all the contained words.
Word editing
Here is the example of an input line and the corresponding OCR result, at the end of the TEXTS step:
| Source | Image |
|---|---|
| Input line | 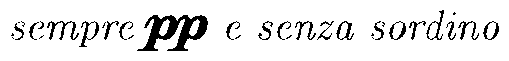 |
| OCR result | 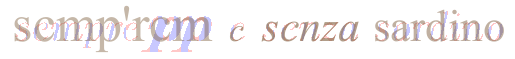 |
Word content
The word “senza” has been OCR’d as “scnza”.
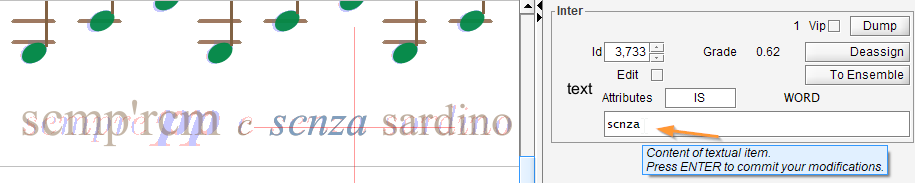
We can modify the content in the text field and press ENTER.
Word attributes
We can do the same content modification for the word “sordino” OCR’d as “sardino”.

But this is not enough. The source was in italic and the result is displayed in upright style.
To fix this, we can now modify the word attributes, via the Attributes field.
For “senza” the OCR’d attributes were “IS” (Italic Serif), while for “sordino” the OCR’d attributes are just “S” (Serif).
So we can simply change the string in the Attributes field to “IS”, and press ENTER.

Handling word attributes is a new feature provided by the 5.6 release.
The attributes, as transcribed by OCR or modified by the user, can be represented by a string composed of the BIUMSC characters.
| Letter | Meaning | Use |
|---|---|---|
| B | Bold | Style |
| I | Italic | Style |
| U | Underlined | - ignored - |
| M | Monospaced | Font type |
| S | Serif | Font type |
| C | Small Caps | - ignored - |
These attributes are used to:
- Choose the text font (based on the
MandSattributes):
The chosen font is Serif (if specified), otherwise Monospaced (if specified), otherwise Sans Serif 1 - Apply a font style (based on the
BandIattributes) : The chosen style is Plain or Bold or Italic or Bold+Italic.
Note: As of this writing, the U (Underlined) and C (Small Caps) attributes are not supported and thus merely ignored.
This results in the possible combinations:
| Type / Style | ( ) Plain | (B)old | (I)talic | (B)old (I)talic |
|---|---|---|---|---|
| ( ) Sans Serif |  |  |  |  |
| (S)erif |  |  |  |  |
| (M)onospaced |  |  | 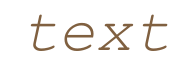 |  |
Word location and size
Still working on the same sentence, the very first word (“sempre”) needs to be fixed:

Modifying the word content and attributes, we get this first result:

The word bounds are too wide when compared to the underlying pixels. To fix this, we have to put the word into the edit mode, either via a double-click on the word, or by ticking the edit checkbox in the InterBoard.

A word being edited shows 2 handles:
- The middle handle can move the word into any direction
- The right handle can increase or decrease the word size (and the related font size accordingly).
Moving the right handle to the left allows to reduce the word width:

And later, in the SYMBOLS step, the “PP” glyph will indeed be recognized as a pianissimo symbol.
Sentence editing
A sentence role can be set to any value among:
- UnknownRole
- Lyrics
- ChordName
- Title
- Direction
- Number
- PartName
- Creator
- CreatorArranger
- CreatorComposer
- CreatorLyricist
- Rights
- EndingNumber
- EndingText
- Rehearsal
- Metronome
Since the 5.2 release, in all cases, we can manually modify the sentence role afterwards, from any role to any other role.

Sentence attributes
New in 5.10
The font attributes of a sentence is initially defined as the “main” attributes found in its word members.
We can now conveniently modify these font attributes, directly at the sentence level.
To do so, we first have to select the sentence, for instance by pointing to one of its words, and then pressing the To Ensemble button.
The Attributes field is still there as for a word, but it now relates to the font attributes of the sentence. We can simply modify the attributes and commit the modifications by pressing the Enter key.
The new font attributes of the sentence are applied transitively to each of its words.
Plain sentence
A “plain” sentence is any sentence which is assigned a role different from Lyrics, ChordName, Rehearsal and Metronome.
Following an OCR recognition (Texts step or manual OCR), the role of each resulting plain sentence is precised. Based on a bunch of heuristics, the engine tries to further distinguish between plain roles like: direction, part name , title, composer, lyricist, etc.
Rehearsal mark
New in 5.10

A rehearsal mark is a short sentence, enclosed in a rectangular box. It is notated in the score for reference during rehearsal.
Since release 5.10, the rehearsal marks are detected by the engine.
Note that, merely because of the enclosure, a mark is not detected and OCR’d during the TEXTS step, but during the CURVES step later.
This mark can be edited like a plain sentence, that is word by word.
It can also be manually inserted via a drag n’ drop action from the Text shape button.
In that case, when the sentence role is set to Rehearsal, a suitable rectangular enclosure is automatically generated around the sentence.
Chord name
A chord name is a musical symbol which names and describes the related chord.
For example: C, D7, F♯, B♭min, Em♭5, G6/B, Gdim, F♯m7, Em♭5, D7♯5, Am7♭5, A(9), BMaj7/D♯.
As of this writing, the Audiveris engine is not yet able to recognize chord names that include true sharp (♯) or flat (♭) characters. Perhaps one day, we will succeed in training Tesseract OCR on this text content.
For the time being, Audiveris is able to recognize such chord names when these characters have been replaced (by OCR “mistake”, or by manual modification) by more “usual” characters:
- '#' (number) as replacement for '♯' (sharp),
- 'b' (lowercase b) as replacement for '♭' (flat).
When we OCR a chord name word, Audiveris may be able to decode it as a chord name and thus wrap it within a chord name sentence.
If Audiveris has failed, we can still force the chord name role (at the sentence level) and type in the missing b or # characters if so needed (at the word level). The chord name will then be decoded on-the-fly with its new textual content.
Note we don’t have to manually enter the true sharp or flat signs. Entering them via their Unicode value is a bit tricky and, in the end, useless.
Instead, when text has been recognized or assigned as a chord name, its internal b or # characters are automatically replaced by their true alteration signs.
For example, we can type “Bb” then press Enter and the chord name will be translated and displayed as “B♭”.
Lyric line
updated in 5.10
A lyric line is a sentence composed of lyric items.
When selected, the Inter board displays additional data:
- Voice number,
- Verse number,
- Location with respect to staff.
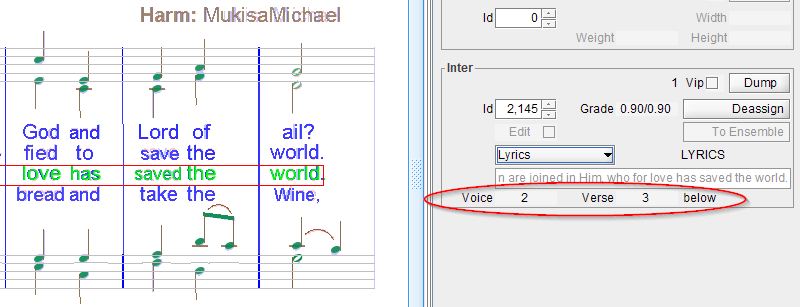
Each syllable (lyric item) is usually linked to a related chord, either above or below.
But it is not always obvious whether the text concerns the staff above or below nor is it always clear which voice is concerned.
If a syllable is not linked to the correct chord, we can modify this link manually by dragging from the syllable to the suitable chord. This will update on-the-fly the line data (voice, verse, location).

Since the 5.10 release, the lyric words are searched for initial numbers.
Such numbers, possibly followed by a period, are generally meant to indicate the verse number as in the example shown above.
- This is redundant with the verse number already computed by the engine and exported to the MusicXML stream.
- When singing the lyrics, we sing the syllables, not these numbers!
- Before the 5.10 release, these numbers were taken as standard syllables and consequently linked to head chords. They were in competition with the real syllables, resulting in a number linked to a voice and the following syllable linked to another voice.
The new policy is as follows:
- The numbers are now recognized as such and not processed as syllables.
- They are no longer linked to a head chord (hence their different color in the display).
- They are not exported to the MusicXML output stream.
There is a risk that a standard word be OCR’d as a number, as the “6” value in the center of the example above.
However:
- This anomaly really stands out in the display, which is a good visual aid.
- The primary cause is that the original accented character
ôwas misinterpreted by the OCR as a character6(even though the OCR was launched on the French language). - It’s rather easy to manually fix the word content on the
Interboard. This will automatically change the word kind from ‘number’ to ‘syllable’.
Metronome mark
Since the 5.4 release, the metronome marks can be automatically recognized.
We can also edit them afterwards and even create new marks from scratch.
A metronome mark is a sentence composed of words.
One of its words is special as it contains not textual characters but music characters. This word is the BeatUnit word.
Editing the metronome is detailed in this specific section.
-
Combining
M(monospaced) andS(serif) could produce a font like “Courier New,” but the result is unsatisfactory. Therefore, in “MS” theMis ignored in favor of theS. ↩